
7 SEO Fails Seen in the Wild (And How You Can Avoid Them) was originally published on BruceClay.com, home of expert search engine optimization tips.
 We often get questions from people wondering why their site isn’t ranking, or why it isn’t indexed by the search engines.
We often get questions from people wondering why their site isn’t ranking, or why it isn’t indexed by the search engines.
Recently, I’ve come across several sites with major errors that could be easily fixed, if only the owners knew to look. While some SEO mistakes are quite complex, here are a few of the often overlooked “head slamming” errors.
So check out these SEO blunders — and how you can avoid making them yourself.
SEO Fail #1: Robots.txt Problems
The robots.txt file has a lot of power. It instructs search engine bots what to exclude from their indexes.
In the past, I’ve seen sites forget to remove one single line of code from that file after a site redesign, and sink their entire site in the search results.
So when a flower site highlighted a problem, I started with one of the first checks I always do on a site — look at the robots.txt file.
I wanted to know whether the site’s robots.txt was blocking the search engines from indexing their content. But instead of the expected text file, I saw a page offering to deliver flowers to Robots.Txt.
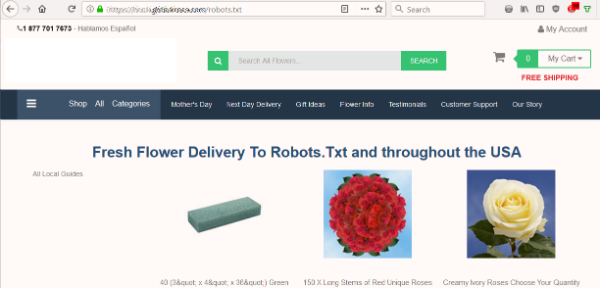
The site had no robots.txt, which is the first thing a bot looks for when crawling a site. That was their first mistake. But to take that file as a destination … really?
SEO Fail #2: Autogeneration Gone Wild
Secondly, the site was automatically generating nonsense content. It would probably deliver to Santa Claus or whatever text I put in the URL.
I ran a Check Server Page tool to see what status the autogenerated page was showing. If it was a 404 (not found), then bots would ignore the page as they should. However, the page’s server header gave a 200 (OK) status. As a result, the fake pages were giving the search engines a green light to be indexed.
Search engines want to see unique and meaningful content per page. So indexing these non-pages could hurt their SEO.
SEO Fail #3: Canonical Errors
Next, I checked to see what the search engines thought of this site. Could they crawl and index the pages?
Looking at the source code of various pages, I noticed another major error.
Every single page had a canonical link element pointing back to the homepage:
<link rel=”canonical” href=”https://ift.tt/2OWooQu; />
In other words, search engines were being told that every page was actually a copy of the homepage. Based on this tag, the bots should ignore the rest of the pages on that domain.
Fortunately, Google is smart enough to figure out when these tags are likely used in error. So it was still indexing some of the site’s pages. But that universal canonical request was not helping the site’s SEO.
How to Avoid These SEO Fails
For the flower site’s multiple mistakes, here are the fixes:
- Have a valid robots.txt file to tell search engines how to crawl and index the site. Even if it’s a blank file, it should exist at the root of your domain.
- Generate a proper canonical link element for each page. And don’t point away from a page you want indexed.
- Display a custom 404 page when a page URL doesn’t exist. Make sure it returns a 404 server code to give the search engines a clear message.
- Be careful with autogenerated pages. Avoid producing nonsense or duplicate pages for search engines and users.
Even if you’re not experiencing a site problem, these are good points to review periodically, just to be on the safe side.
Oh, and never put a canonical tag on your 404 page, especially pointing to your homepage … just don’t.
SEO Fail #4: Overnight Rankings Freefall
Sometimes a simple change can be a costly mistake. This story comes from an experience with one of our SEO clients.
When the .org extension of their domain name became available, they scooped it up. So far, so good. But their next move led to disaster.
They immediately set up a 301 redirect pointing the newly acquired .org to their main .com website. Their reasoning made sense — to capture wayward visitors who might type in the wrong extension.
But the next day, they called us, frantic. Their site traffic was nonexistent. They had no idea why.
A few quick checks revealed that their search rankings had disappeared from Google overnight. It didn’t take too much Q&A to figure out what had happened.
They put the redirect in place without considering the risk. We did some digging and discovered that the .org had a sordid past.
The previous owner of the .org site had used it for spam. With the redirect, Google was assigning all of that poison to the company’s main site! It took us only two days to restore the site’s standing in Google.
How to Avoid This SEO Fail
Always research the link profile and history of any domain name you register.
A qualified SEO consultant can do this. There are also tools you can run to see what skeletons may be lying in the site’s closet.
Whenever I pick up a new domain, I like to let it lie dormant for six months to a year at least before trying to make anything of it. I want the search engines to clearly differentiate my site’s new incarnation from its past life. It’s an extra precaution to protect your investment.
SEO Fail #5: Pages That Won’t Go Away
Sometimes sites can have a different problem — too many pages in the search index.
Search engines sometimes retain pages that are no longer valid. If people land on error pages when they come from the search results, it’s a bad user experience.
Some site owners, out of frustration, list the individual URLs in the robots.txt file. They’re hoping that Google will take the hint and stop indexing them.
But this approach fails! If Google respects the robots.txt, it won’t crawl those pages. So Google will never see the 404 status and won’t find out that the pages are invalid.
How to Avoid This SEO Mistake
The first part of the fix is to not disallow these URLs in robots.txt. You WANT the bots to crawl around and know what URLs should be dropped from the search index.
After that, set up a 301 redirect on the old URL. Send the visitor (and search engines) to the closest replacement page on the site. This takes care of your visitors whether they come from search or from a direct link.
SEO Fail #6: Missed Link Equity
I followed a link from a university website and was greeted with a 404 (not found) error.
This is not uncommon, except that the link was to /home.html — the site’s former homepage URL.
At some point, they must have changed their website architecture and deleted the old-style /home.html, losing the redirect in the shuffle.
Ironically, their 404 page says you can start over from the homepage, which is what I was trying to reach in the first place.
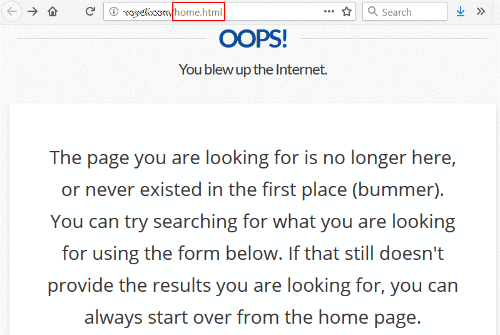
It’s a pretty safe bet that this site would love to have a nice link from a respected university going to their homepage. And accomplishing this is entirely within their control. They don’t even have to contact the linking site.
How to Fix This Fail
To fix this link, they just need to put a 301 redirect pointing /home.html to the current homepage. (See our article on how to set up a 301 redirect for instructions.)
For extra credit, go to Google Search Console and review the Index Coverage Status Report. Look at all of the pages that are reported as returning a 404 error, and work on fixing as many errors here as possible.
SEO Fail #7: The Copy/Paste Fail
The site redesign launches, the canonical tags are in place, and the new Google Tag Manager is installed. Yet there are still ranking problems. In fact, one new landing page isn’t showing any visitors in Google Analytics.
The development team responds that they’ve done everything by the book and have followed the examples to the letter.
They are exactly right. They followed the examples — including leaving in the example code! After copying and pasting, the developers forgot to enter their own target site information.
Here are three examples our analysts have run across in website code:
- <link rel=”canonical” href=”https://ift.tt/1yfAz1j;>
- ‘analyticsAccountNumber’: ‘UA-123456-1’
- _gaq.push([‘_setAccount’, ‘UA-000000-1’]);
How to Avoid This SEO Fail
When things don’t work right, look beyond just “is this element in the source code?” It may be that the proper validation codes, account numbers and URLs were never specified in your HTML code.
Mistakes happen. People are only human. I hope that these examples will help you avoid similar SEO blunders of your own.
But some SEO issues are more complex than you think. If you have indexing problems, then we are here to help. Call us or fill out our request form and we’ll get in touch.
Like this post? Please subscribe to our blog to have new posts delivered to your inbox.
from Bruce Clay, Inc. Blog https://ift.tt/2Tvm7iF


No comments:
Post a Comment