
Good SEO reporting is tough. There’s so much conflicting and outdated advice in our industry that in many cases, SEOs tend to focus on buzz terms rather than good actionable advice.
I’ve seen hundreds of SEO reports throughout the years and I often have hard time walking out with a good plan of further action when it comes to making a website better optimized.
But it’s not the point of this article. What I’d like to start here is an open-ended discussion: Which SEO issues do you include in your SEO audits that others don’t?
Inspired by some recent SEO audits, here are three important SEO issues that I notice are often overlooked:
1. Trailing slash / No trailing slash
One of the most under-estimated issues with structuring URLs is double-checking whether your URLs work with and without a trailing slash at the end.
Read my old article on the issue which, despite being published all the way back in 2009, still holds true.
To summarize:
- The best practice is to have both versions work properly
- Google’s official recommendation is 301-redirecting one version to the other, which is something your client wants to do even if both versions work
- Apart from accidental broken links (e.g. some HTML editors add / at the end of the URL automatically), this could result in lower rankings and lost traffic/conversions (e.g. when other websites link to the broken version of the page)
To diagnose the issue, I tend to use the free website crawler from SEOchat. For some reason it catches these issues more often than other crawlers.
You can also simply run a couple of random URLs through a header checker to see that no link power is being leaked and no users are being lost.

Further reading: There’s another guide explaining problems and solutions when it comes to a trailing slash.
- Implement 301 (permanent) redirects from one version to the other through your .htaccess file.
- If you can’t use permanent redirects, use canonical elements instead – either will reduce the risk of duplicate content [Note: This solution is only valid when both versions actually work, so there will be no broken links]
- Be consistent with your choice.
2. No H-subheads
A long time ago, we used to call those h2-h3 subheadings “semantic structure”, and we’d recommend using them to give keywords higher prominence.
H1 – H6 tags “briefly describe the topic of the section they introduce”. They can “be used by user agents, for example, to construct a table of contents for a document automatically“.
Other than that there was no obvious tangible benefit to using them.
These days, everything has changed because using H2 tags and including your keyword in them can get you featured!
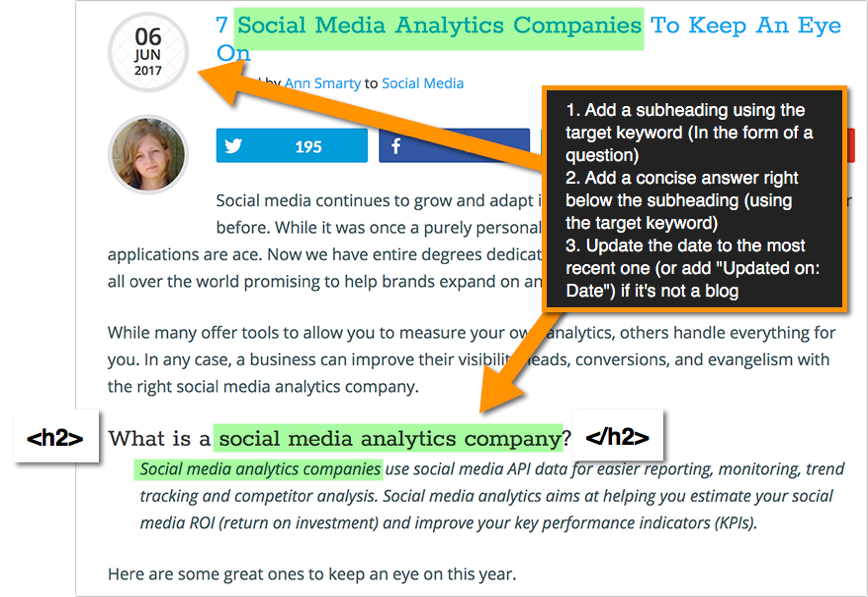
Image taken from my Featured Snippets FAQ on Content Marketing Institute, where I explain how <h2> tags can help you get a featured snippet
The featured snippet algorithm is being changed daily, so it is going to be harder and harder to get featured. So far, though, they work like a charm and thanks to that, you have a very obvious reason to convince your clients to start using these tags: They can help you get featured!
Netpeak Spider is an excellent tool to diagnose H-structure of the whole website. It gives a detailed report containing content and number of H1-H6 tags, missing tags, and more:

3. Thin content
How do we define thin content?
- Little original content on the page (usually, just a paragraph or two)
- Lack of positive signals (links, clicks/traffic, mentions/shares. The latter is mostly an indicator of user engagement)
Everyone talks about thin content in our industry, but an alarming number of SEO reports fail to include it.
Why so? I see two reasons:
- Thin content is hard to diagnose
- Thin content is hard to explain (how to convince a client of a 100,000-page website to invest in editing existing content and consolidating lower-quality pages)
When it comes to diagnosing, I’d like to direct you to the awesome audit template from Annie Cushing. It does include thin content diagnostics and even explains how to find it.
As to explaining the issue to clients, the problem with thin-content pages is that it can negatively affect the whole site. If a search crawler finds a high percentage of thin content on a website, it may decide that the whole site is not of much value either. That’s the essence of the Panda update (which is now part of Google’s algorithm).
For more context, check out this video by Jim Boykin:
Whenever your site is affected, almost always the answer is “You have too much thin content”
That being said, thin content may be a reason of your client’s website slowly but surely losing its rankings. It’s very tough to diagnose:
- There are no longer thin-content-related updates being announced.
- The loss of rankings is very gradual making it hard to pin-point when and why it started
- Pages losing rankings may be of better quality than the rest of your website. Thin content may not have ranked for ages. What’s new is that they may now start negatively effect pages that do rank.
Like duplicate content, it’s not right to call this a penalty. Even though thin content may be dragging your site down, it’s not a penalty. It’s part of Google’s effort to keep its results higher-quality.
What other SEO issues do you consider often overlooked in our industry? Share your insights!
from Search Engine Watch http://ift.tt/2EJmYbT


No comments:
Post a Comment